🚀 DS SERVE: A Framework for Efficient and Scalable Neural Retrieval
1University of California, Berkeley 2University of Illinois Urbana–Champaign 3University of Washington
*Equal contribution.
[Web Interface] [API Endpoint] [Voting System] [Code] [Paper]
- You can turn any large in-house dataset (<1T tokens) into a high-throughput (up to 10000 index-only QPS), memory-efficient (<200 GB RAM) retrieval system with a web UI and API.
- Our prototype, built on 400B words of high-quality LLM pre-training data, is readily available and provides downstream gains comparable to commercial search engine endpoints.
DS Serve UI
Why was it previously challenging?
- Scaling neural retrieval is hard. Achieving high throughput, low memory use, and strong accuracy on very large datasets is non-trivial—traditional linear scan is simply infeasible.
- Widely used ANN methods don’t scale gracefully. At large scales, IVFPQ suffers from inefficient latency–performance tradeoffs and quantization errors, while HNSW demands substantial RAM, making modest deployments impractical.
- End-to-end tooling is lacking. Few frameworks offer a ready-to-use retrieval stack with a web UI, API endpoints, and built-in feedback collection.
As an example, most users default to search engines for general knowledge queries even when high-quality web data (e.g., LLM pre-training corpora) is publicly available. However, those engines are costly, low-throughput, and often unreliable at scale.
DS Serve addresses these challenges by making it easy to transform any large-scale in-house dataset into a high-throughput, memory-efficient neural retrieval system backed by DiskANN—complete with a web UI, API endpoints, and mechanisms for collecting search-result feedback. Our prototype (400B tokens, 2B vectors, 5 TB embeddings) matches the downstream gains of commercial search endpoints and, to the best of our knowledge, is the largest publicly accessible vector store.

DS SERVE converts the largest pretraining dataset into an efficient neural retrieval system: a query q retrieves relevant text via ANN (IVFPQ or DiskANN), optionally reranks with exact and/or diverse search, and returns the top-k chunks with voting options for user feedback.
See below for a set of new applications our framework enables, our detailed system design, and performance benchmarks!
Application
We envision DS Serve enabling a range of high-impact applications:
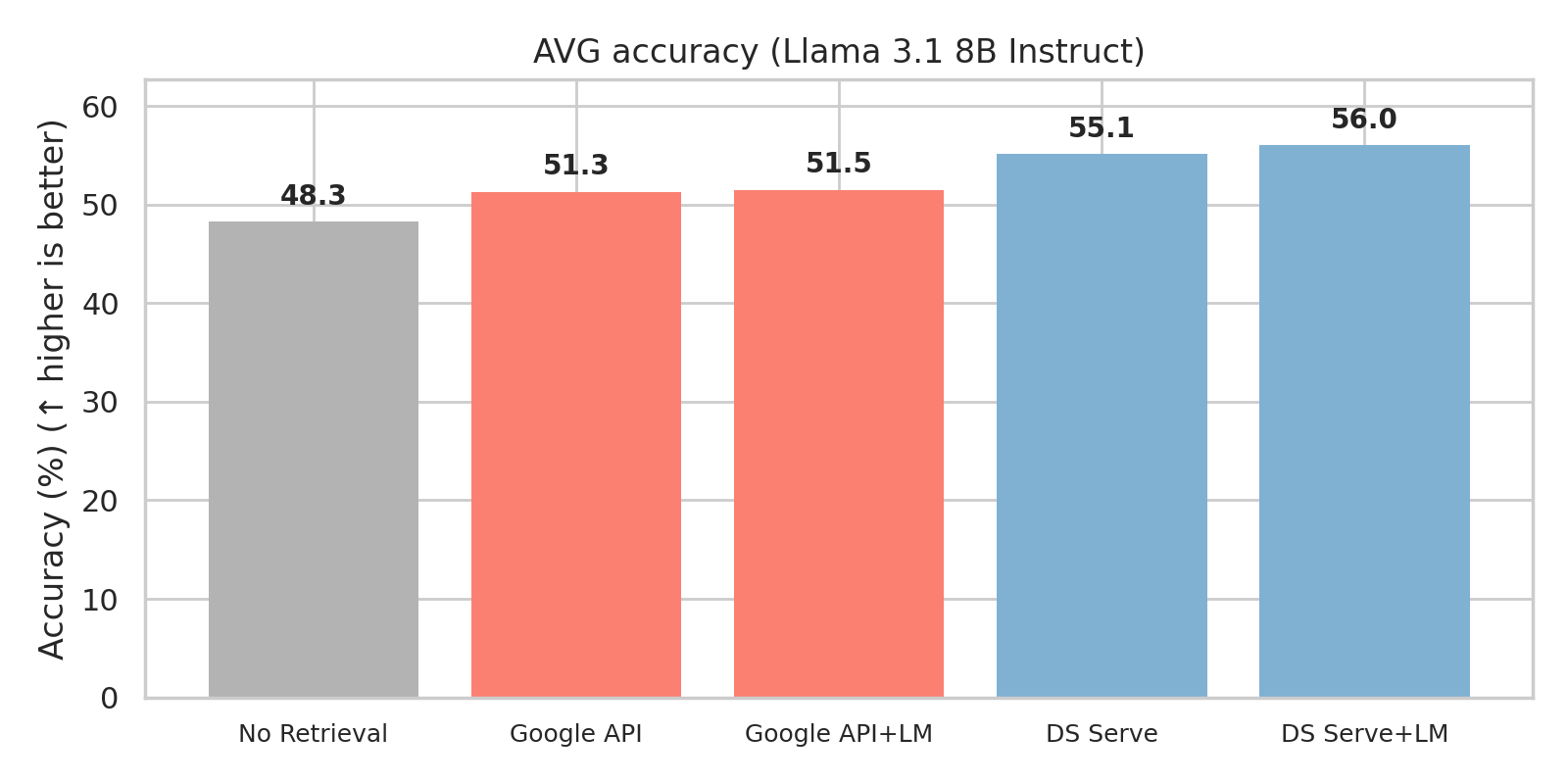
- Retrieval-Augmented Generation (RAG): DS Serve powers efficient RAG by feeding high-quality search results into LLMs. As shown in the Performance section, it delivers superior accuracy and latency compared to both open-source baselines (like IVFPQ) and commercial search endpoints.
- Data Attribution & Curation: By indexing entire pre-training corpora, DS Serve enables semantic data attribution, complementing n-gram based systems like OLMoTrace. It also facilitates advanced curation—allowing semantic deduplication, decontamination, and customized filtering for query-specific datasets.
- Training Search Agents: Training deep-research agents requires high-frequency search rollouts that are often cost-prohibitive on commercial engines. DS Serve provides a free, high-throughput backend where developers can control latency-accuracy tradeoffs without rate limits.
- Pushing the Frontier of Search: While traditional search engines struggle with long or complex queries, our vector-based approach handles them effectively. Additionally, the built-in voting system collects real-world labeled data to help build realistic benchmarks for retrieval research.
Concrete project ideas:
1. Robust Data Attribution & Novelty Detection
Researchers working on novelty detection (e.g., Un-Attributability) have found that embedding similarity is significantly more robust to paraphrased or long-context queries compared to traditional N-gram matching. However, building the necessary indices often requires expensive distributed setups. DS Serve provides an off-the-shelf solution for semantic attribution over pre-training corpora.
2. Removing Bottlenecks in RL Training
Recent work in reinforcement learning (see Dr. Tulu, §5.1) highlights that search engine API rate limits often bottleneck training speed, rendering increased compute ineffective during rollouts. This limitation is also a key motivation for approaches like ZeroSearch. DS Serve offers a high-throughput, rate-limit-free backend that enables search-intensive RL loops to scale efficiently.
3. Efficient Test-Time Training (TTT)
Prior approaches to retrieval-augmented TTT (e.g., TTT for LLM) have required massive resources—using up to 180 servers to achieve ~1.35s/query over just 810B tokens (~810G vectors). In contrast, DS Serve delivers low-latency retrieval over 5TB of embeddings (~2B vectors) with a fraction of the hardware footprint.
Technical design
Datastore
Prior work showed that retrieval over large pre‑training corpora can improve RAG accuracy (see RETRO, MassiveDS, CompactDS); however, accessible frameworks with modest resources have been lacking. DS SERVE is built on CompactDS, a 380‑billion‑word corpus (~2B vectors) spanning web crawl data, Wikipedia, research papers, and more, because it is demonstrated to be comparable in coverage to a much larger, noisier Common Crawl data.
This represents a significantly larger datastore than most prior work, and to the best of our knowledge is the largest datastore that is publicly available for neural retrieval. Typical evaluations run at much smaller scales (often ≤ tens of millions of vectors), e.g., MS MARCO, and Wikipedia, as well as consolidated leaderboards such as BEIR. Even advanced commercial vector databases commonly impose per‑namespace/index limits well below the billion‑vector regime; see pricing/capacity notes for Turbopuffer.
Scalable and efficient search
What is Approximate Nearest Neighbor (ANN) search?
First, a database is embedded into a collection of vectors named datastore D. Then an index over D is built for easy lookup. Given a user query q, ANN returns the nearest neighbors—the vectors in D most semantically similar to q—through approximation. By visiting only part of the index, ANN retrieves faster than exhaustive search, which is infeasible at a billion‑vector scale. Therefore, ANN optimizes for latency with a small tradeoff in recall.
The Challenge: IVFPQ and the Accuracy-Latency-Memory Tradeoff
Most researchers and existing frameworks (including the CompactDS paper) relying on IVFPQ (Inverted File with Product Quantization) have been struggling with the accuracy-latency-memory tradeoffs. At the billion-vector scale, IVFPQ requires heavy quantization to fit in RAM (sacrificing accuracy) or consumes excessive memory. Furthermore, increasing accuracy (e.g., larger nprobe) drastically reduces throughput.
The Solution: DiskANN
DS Serve addresses this by incorporating DiskANN, which significantly outperforms IVFPQ. By storing compressed vectors in RAM and full-precision vectors with the navigation graph on NVMe SSDs, DiskANN breaks traditional bottlenecks through implicit reranking during graph traversal.
IVFPQ vs. DiskANN
| Feature | IVFPQ (Traditional) | DiskANN (DS Serve) |
|---|---|---|
| Accuracy | Lower: Quantization noise reduces recall. | Higher: Full-precision vectors on disk ensure high recall. |
| Throughput | ~100 QPS: More distance computations. | >10,000 QPS: Fewer distance computations using advanced data structure (navigation graph) and massively parallel I/O. |
| Latency | Higher: Sequential inverted list scanning. | Lower: Efficient graph traversal. |
We support both backends, but DiskANN is the recommended default for all high-performance deployments. DiskANN achieves >10,000 index-level QPS and 200+ end-to-end QPS with ~200 GB RAM, making it ideal for high-throughput deployments while maintaining competitive accuracy. In our internal evaluations, DiskANN’s implicit reranking improved downstream accuracy compared to pure ANN and, on some tasks (e.g., MMLU), matched or exceeded exact search. Detailed benchmarks are provided below.
How DiskANN works (details)
DiskANN stores compressed vectors in RAM and full-precision vectors with graph adjacency lists on SSD. Search begins with a candidate queue ordered by approximate distances from compressed vectors. At each step, the algorithm selects the nearest unvisited node, fetches its exact vector and adjacency list from SSD to refine the distance, then evaluates its neighbors using compressed representations. This alternates between compressed-distance frontier expansion and selective SSD loading for refinement until convergence. By loading only essential high precision data per query, DiskANN scales to billion-scale datasets while maintaining strong recall.
Diverse Search & Exact Search
Diverse Search (available on UI) applies MMR to reduce redundancy: Score(i) = λ·sim(q,d_i) − (1−λ)·maxj∈S sim(d_i,d_j). Enable this when results contain noticeable duplicates or near-duplicates.
Exact Search (requires GPU, not on public UI) reranks ANN candidates by recomputing exact similarity scores using GritLM. This improves accuracy for harder queries and benefits from caching for repeated or similar queries. To enable Exact Search, build from source with a dedicated GPU.
For fastest latency/QPS, keep both toggles off. Use Diverse Search to de-duplicate results; use Exact Search when accuracy is critical and you have GPU compute available.
Deploying large-scale retrieval systems comes with unique challenges. We have documented our experiences and best practices—specifically focusing on optimizing DiskANN in our engineering blog post: How to Build and Use DiskANN Perfectly.
Performance
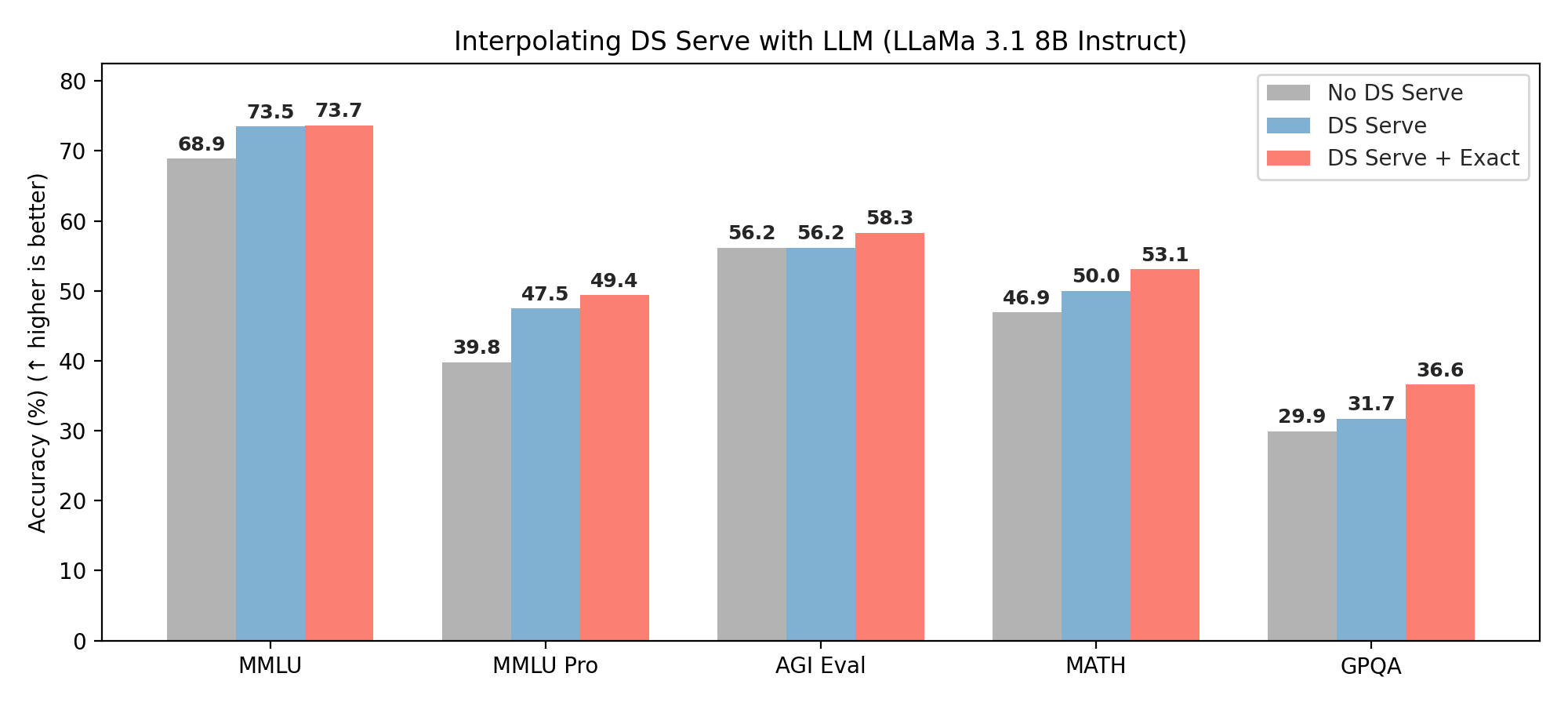
Interpolating DS Serve with LLM
Downstream accuracy (%) with LLaMa 3.1 8B Instruct. DS Serve consistently improves accuracy across reasoning-intensive benchmarks; adding Exact Search provides further gains. We use K=1000, k=10, and nprobe=256.
DiskANN vs IVFPQ
DiskANN is more accurate and faster than IVFPQ. At recommended configs (DiskANN L=2000, IVFPQ nprobe=256), DiskANN achieves ~2.3× higher throughput and ~2.2× lower latency. The internal DiskANN index reaches up to 10,000 QPS; DiskANN is the recommended default. Accuracy comparison uses DiskANN L=2000 and IVFPQ nprobe=256 on TriviaQA and Natural Questions.
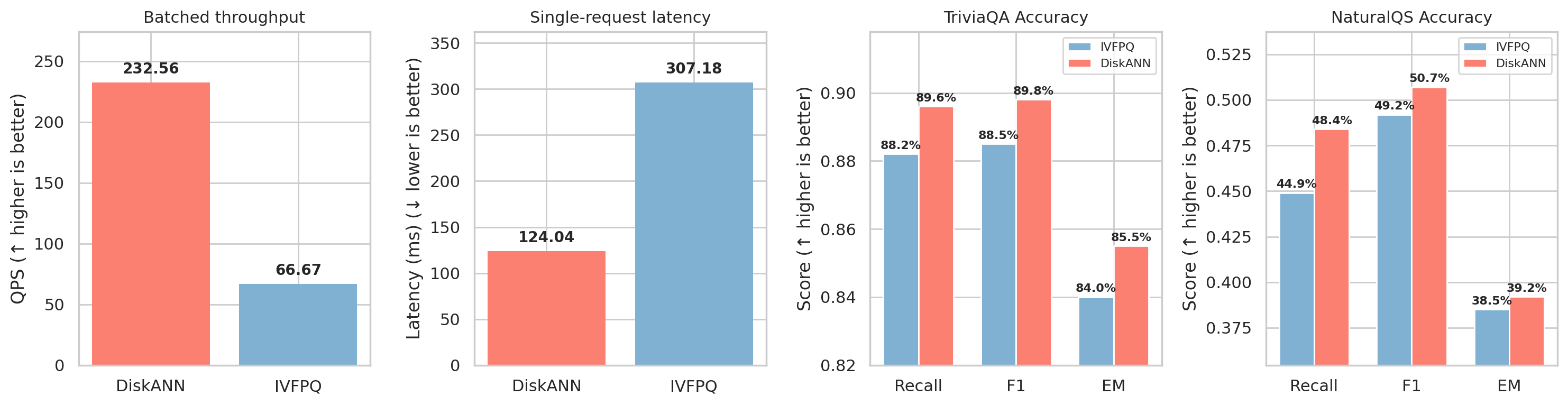
Accuracy metrics: Recall measures whether the LLM's answer contains the correct answer; EM (Exact Match) measures whether the LLM's answer exactly matches the correct answer after normalization; F1 measures word-level overlap between the LLM's answer and the correct answer. IVFPQ remains available as a legacy option.
DS Serve vs Google Custom Search (CSE) API
Latency (single-request), throughput (batched), and downstream accuracy comparison. Accuracy is averaged over MMLU, MMLU Pro, AGI Eval, GPQA, and MATH using LLaMa 3.1 8B Instruct (see CompactDS Table 8). Google CSE results use the official Custom Search JSON API, please check the linked documentation for use guide.
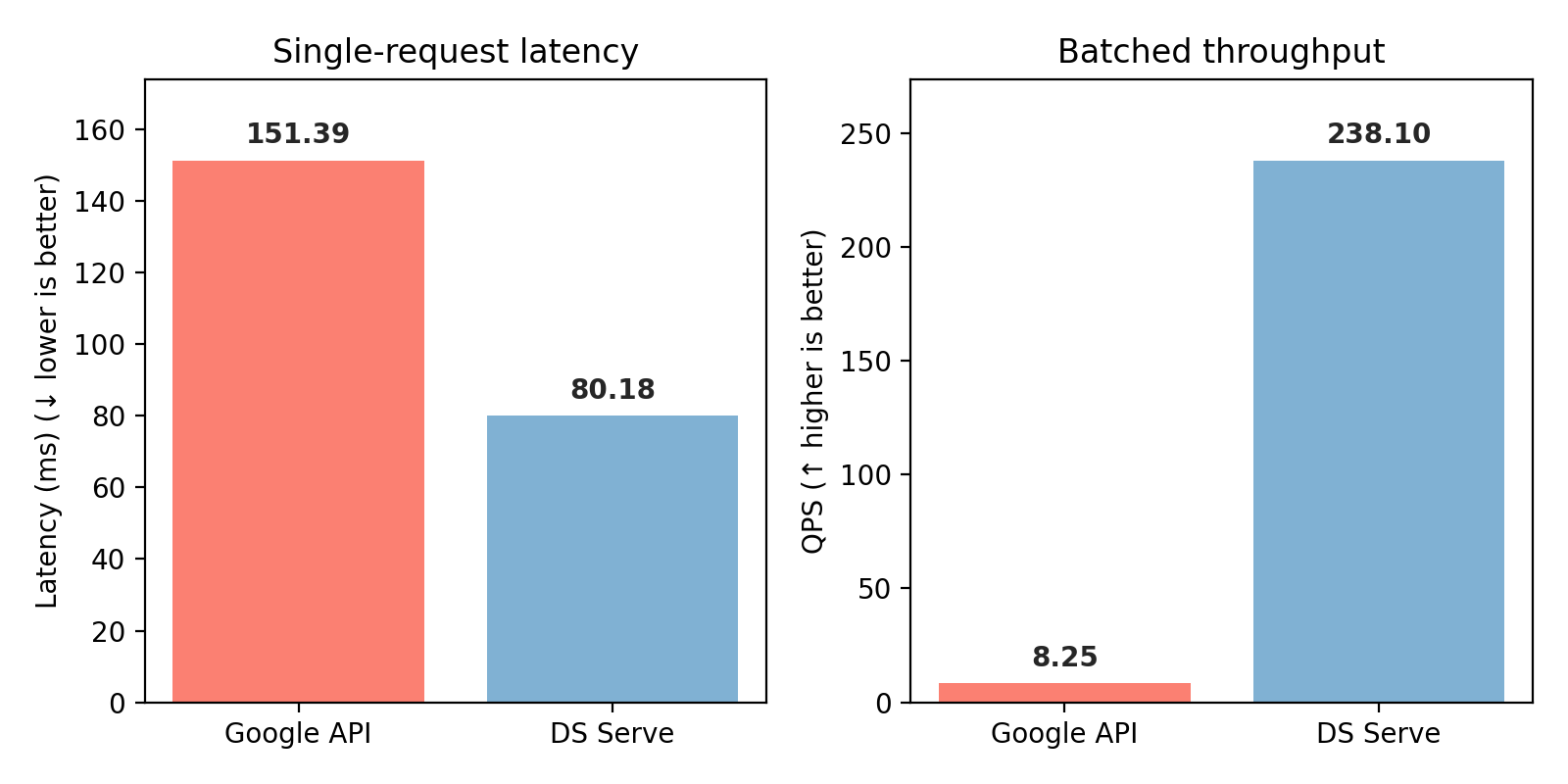
DS Serve (backed by CompactDS) achieves better downstream accuracy than Google CSE and it's also capable to offer ~30× higher throughput (batched) and ~2× lower latency (single-request)—all free of any API costs. We aim to reach 10,000 QPS end-to-end, matching the internal index-only throughput.
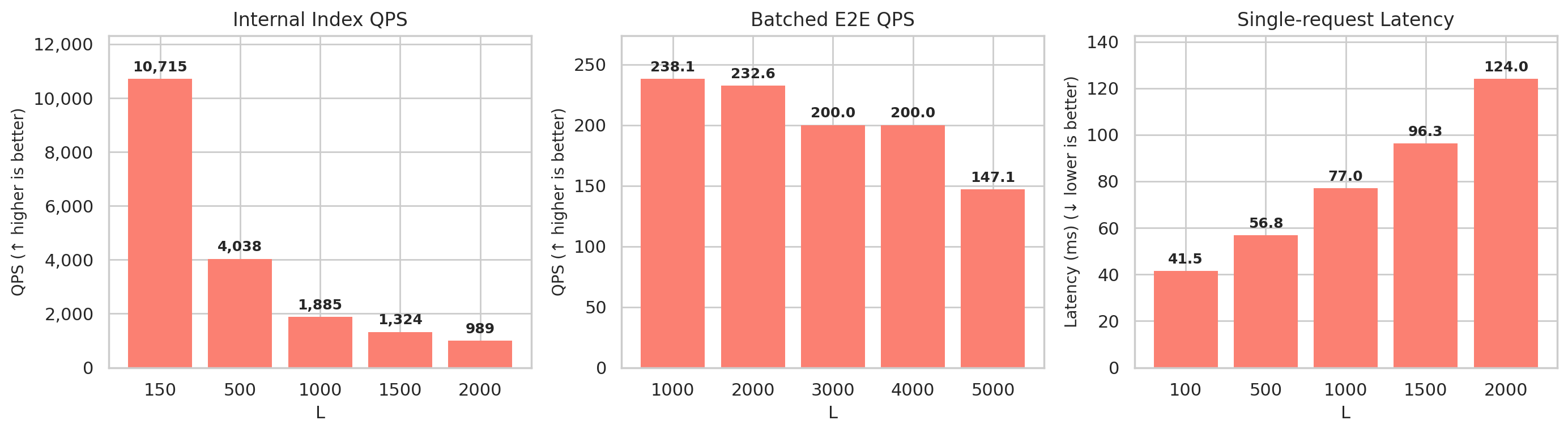
DiskANN Search Complexity (L) Ablation
The search list size L controls the accuracy–latency tradeoff in DiskANN. L≈100 is sufficient for most queries; higher L improves accuracy for harder queries while remaining fast. Internal QPS reflects raw index throughput without embedding or network overhead—our goal is to close the gap between internal and end-to-end QPS through future optimizations.
Acknowledgements
We thank the following open‑source projects and communities:
- CompactDS — for the diverse, high-quality, web-scale datastore that powers DS Serve’s retrieval capabilities.
- Massive Serve — for the serving infrastructure and deployment utilities that power DS Serve.
- IVFPQ and DiskANN — for enabling high‑performance ANN search at scale.